
متصفح Brave اضاف مؤخرا القدرة على استضافة مساعد LEO محليا باستخدام Ollama
هذا شرح قصير عن تشغيل LEO محليا بستخدام برمجية Ollama على دوكر. استخدام دوكر يسهل تثبيت Ollama خاصة على كروت AMD, لان سيختصر كل اعداد التعريفات
Ollama اعداد
CPU
| |
ROCm
| |
CUDA
ستحتاج لتثبيت ادوات أنڤيديا للحاويات (nvidia container toolkit) كامل التفاصيل موجوده على صفحة Ollama على docker hub.
| |
Downloading an LLM
ستحتاج لاختيار موديل يتسع على ذاكرة كرت الشاشة الخاص بك. هناك نسخ “quantized” من LLMs تكون اصغر وتعمل بذاكرة اقل. ادخل الى صفحة الLLM وابحث في قائمة الاصدارات عن نسخه تتسع على الكرت الخاص بك.
بامكانك معرفة ابرز الLLMs على صفحة Lmsys’s chatbot arena Leaderboard, ترتب الموديلات على حسب تقييمات المستخدمين. https://lmarena.ai/
موديلات LLAMA 3 من ميتا هي الاشهر الحاليا.
| |
هذا الامر سيقوم بتنزيل الموديل الى مجلد ./ollama المربوط في دوكر.
استخدام LEO مع الموديل المحلي
أذهب الى الاعدادات ثم صفحة Leo
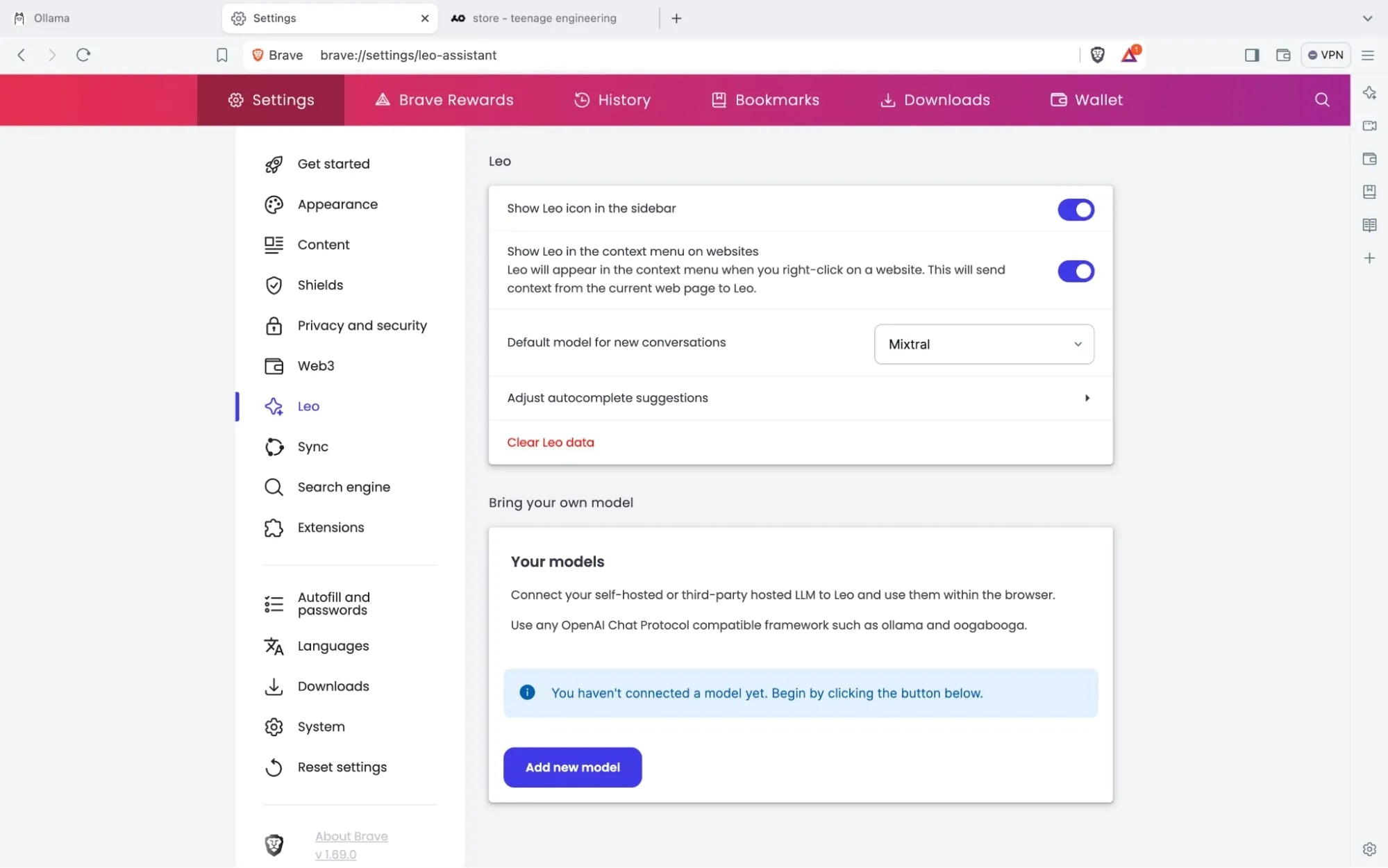 (صور من Brave)
(صور من Brave)
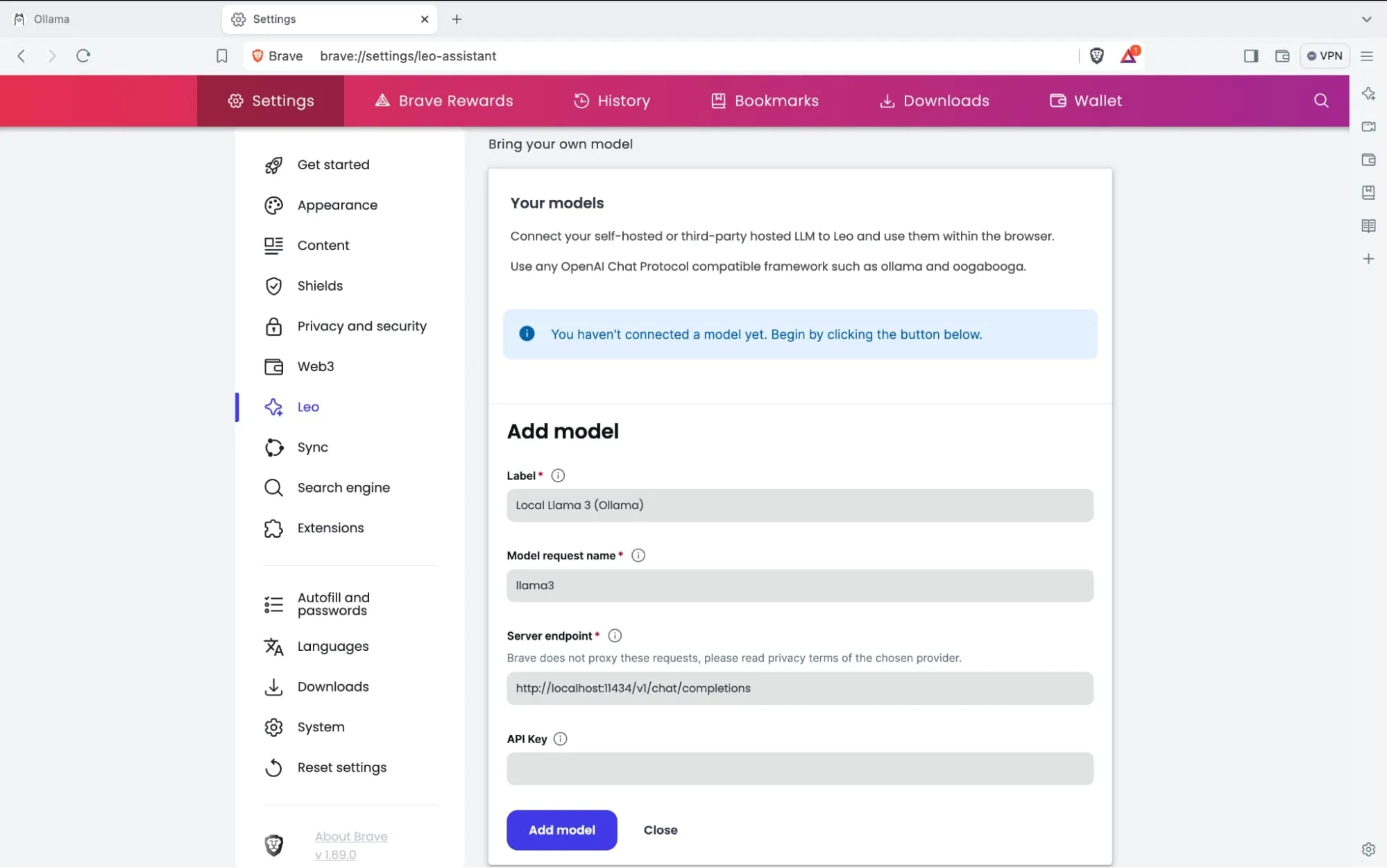
ال model request name هو نفس اسم الموديل في Ollama, أي: llama3:YOUR_TAG
عنوان الخادم سيكون دائما: http://localhost:11434/v1/chat/completions الا اذا تستضيف Ollama على خادم اخر او غيرت المنفذ.
تاكد من اختيار الموديل المحلي عند استخدام leo.
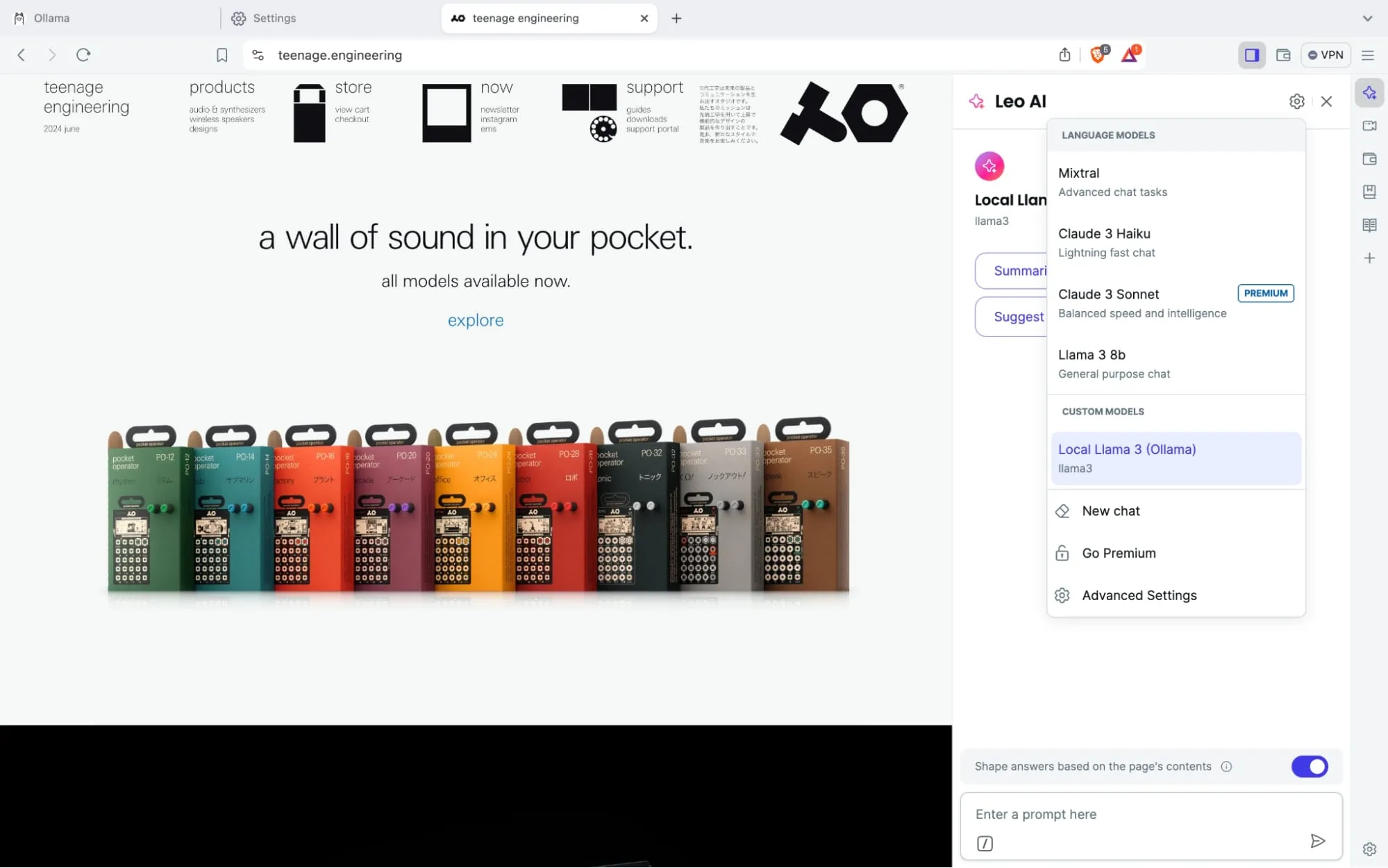
والان اصبح لديك مساعد ذكاء اصطناعي مدمج في المتصفح ويعمل محليا مع خصوصية تامه!